GPGPU(General Purpos GPU): CPU가 처리하던 연산을 GPU로 수행하는 것GPGPU(General Purpos GPU): CPU가 처리하던 연산을 GPU로 수행하는 것
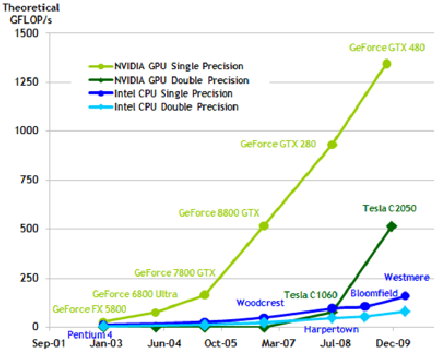
GPU의 연산이 CPU의 연산 속도를 넘어서기 시작했다.
사실 GPU와 CPU은 서로 다른 특징에 따라 더 잘하는 연산이 존재한다. ( GPU는 단순한 연산을 빠르게 하는 것이다. )
병렬 처리

병렬 처리: 하나의 큰 문제를 여러 개의 연산 자원을 활용해서 해결하는 것이다.
컴퓨팅 아키텍처의 발전 경향
1. 2000년 초반까지는 연산코어에 트랜지스터를 많이 집어넣는 방향으로 속도를 높여왔다
한계점: 트랜지스터를 많이 사용할 수록 전기를 많이 소모한다 -> 전기를 많이 사용할 수록 열이 많이 발생한다 -> 좁은 공간에서 많은 열이 발생하면 연산 오류를 발생시킨다.
2. 하나의 칩에 연산코어를 많이 넣는 방향으로 바꼈다.
최근 CPU에는 수개에서 많개는 수십개의 연산코어를 가지고 있다. GPU는 수백개에서 수천개를 가지고 있다.
왜 공부해야되는데요?
Q. 병렬 처리 지시어가 있잖아요
-> 효율적이지 못할 수도 있다. 심지어 잘못된 값, 낮아진 성능이 발생할 수 있다.
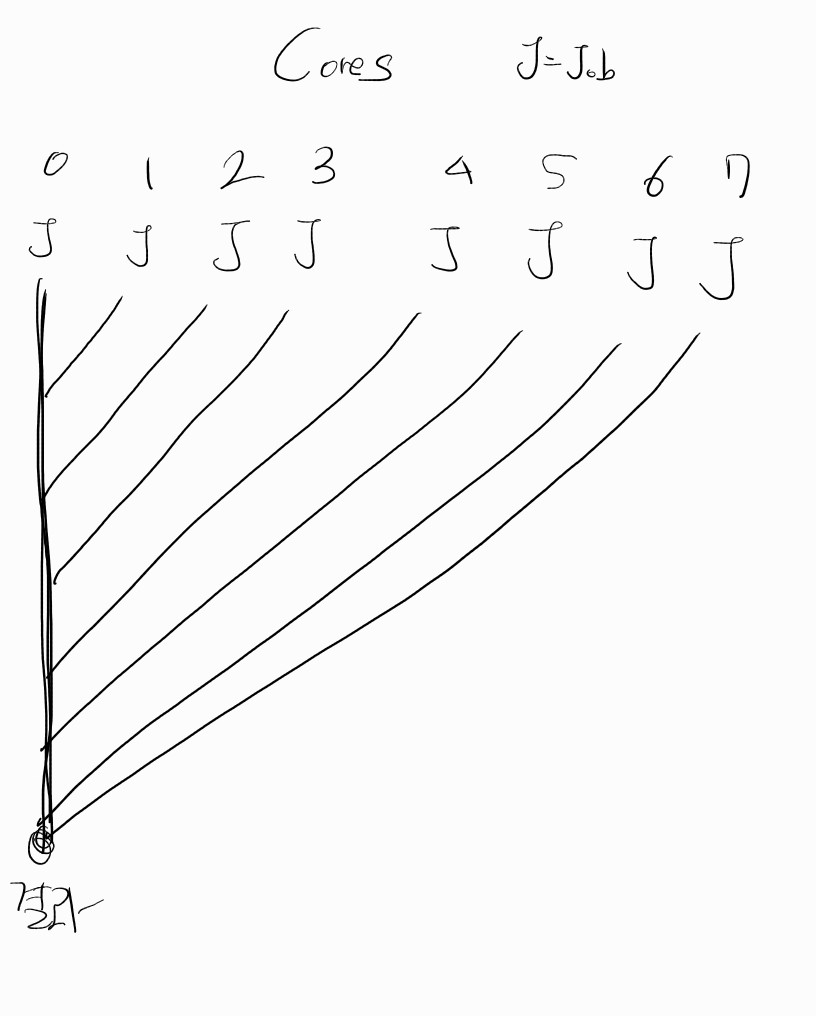
8개의 코어가 있고
해야될 일을 J(Job)으로 표현했다.
0~7번의 코어가 병렬로 처리되었고, 합산은 0번 코어에서 다했다고 생각해보자
그럼 아래와 같은 그림이 나올 것이다.
하지만 이런 방법도 있다.
결과를 합칠 때도 하나의 코어에서 처리하는 것이 아닌,
병렬로 처리하는 것이다.
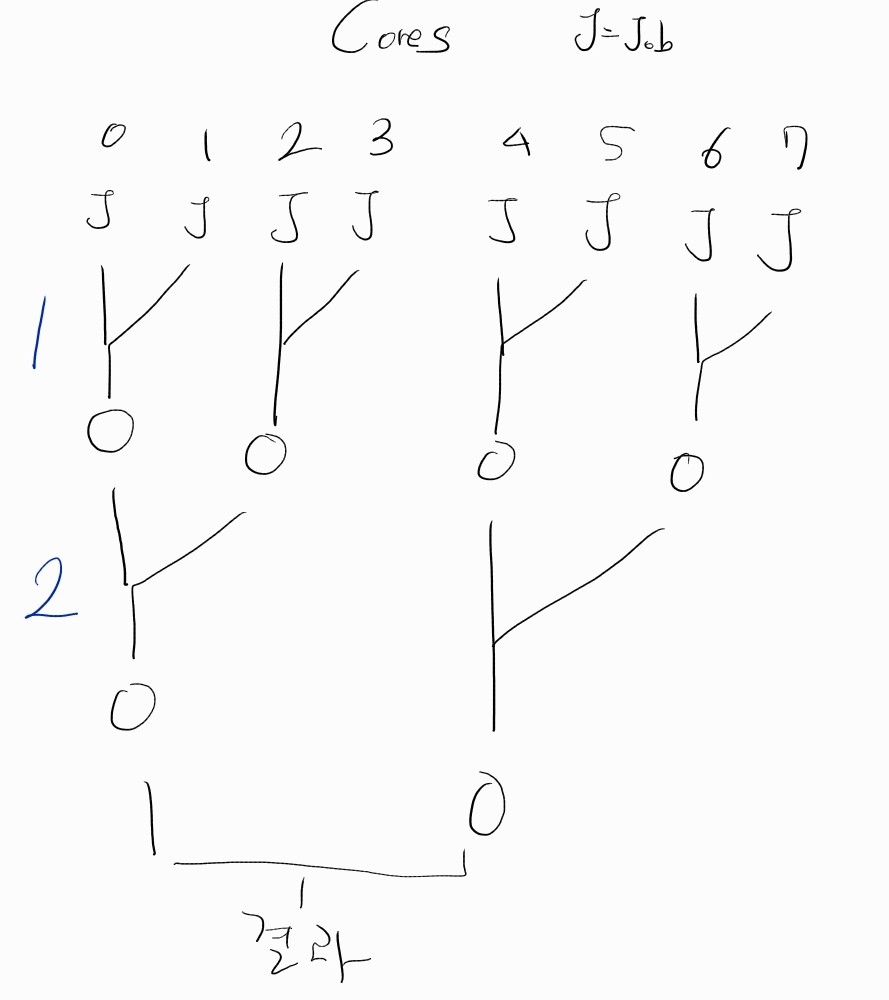
1번 방법으로 하면 코어가 많아 질 수록 어느시점에서는 오히려 시간이 늘어난다. ( N/P + (P - 1))
하지만 2번 방법으로 할 시에는 시간이 계속 줄어드는 모습을 볼 수 있다 (N/P + logN)
(N: 해야 될 일, P: 코어 수)
플린 분류법

- SISD(Single Instruction Single Data): 단일 데이터에 단일 명령어를 실행한다.
- 직렬처리 연산 장치
- SIMD(Single Instruction Multi Data): 복수 데이터에 단일 명령어를 실행한다.
- 병렬처리에 사용되는 아키텍처
- MISD(Multi Instruction Single Data): 단일 데이터에 단일 데이터를 실행한다.
- 개념적으로만 기술되는, 아직 실현되지 않은 컴퓨터 아키텍처이다.
- MIMD(Multi Instruction Multi Data): 복수 데이터에 복수 명령어를 실행한다
- 병렬처리에 사용되는 아키텍처
MIMD (ex. CPU)
SISD가 하나의 칩 안에 들어있는 구조라고 생각하면 된다.
MIMD는 여러 연산 유닛(또는 프로세서)이 서로 다른 명령어를 처리하고, 각 연산 유닛은 서로 다른 데이터를 동시에 처리하는 구조를 의미한다. 즉, 각 코어는 독립적으로 동작하며, 다른 작업을 병렬로 처리할 수 있다.
MIMD 기반 병렬 처리는 각 스레드에 독립된 작업(task)들을 분배하는 경우가 많으며, 이러한 병렬 처리 기법을 태스크 수준 병렬화(task-level parallelism)라고 한다.
SIMD (ex. GPU)
벡터 프로세서, 배열 프로세서라고도 불린다. SIMD는 한 번에 하나의 명령어를 실행하지만, 여러 데이터에 그 명령어를 동시에 적용하는 방식이다. 즉, 같은 연산을 여러 데이터에 동시에 수행함으로써 처리 속도를 높일 수 있어.
만약 인덱스 16개를 사용고, 각각의 인덱스 합을 구하려 하고 있고, 연산 유닛이 4개가 있다면
4개의 연산 유닛이 한 번의 연산주기마다 0~3, 4~7, 8~11, 12~15 인덱스에 접근해서 16번의 주기가 아닌 4번의 주기만에 끝낼 수 있다.
동일한 연산을 동시에 여러 데이터에 적용한다는 의미에서 데이터 수준 병렬화(data-level parallelism)이라고 부른다.
글과 그림을 보면 이해가 잘 될 것이다.

메모리 공유 방식
1. 공유 메모리 시스템 (Shared Memory System)
- 병렬 처리 시스템 내에서 여러 연산 유닛들이(프로세서들이) 하나의 물리적인 메모리 공간을 공유하는 시스템입니다. 모든 프로세서가 동일한 메모리 자원을 사용할 수 있으므로, 각 프로세서가 같은 데이터를 동시에 접근하고 수정할 수 있습니다.
- 여러 스레드가 같은 메모리 공간에 동시에 접근할 수 있기에 메모리 접근 시 주의가 필요하다. (동기화 필요)
- ex) CPU, GPU, 멀티코어 프로세서가 있는 컴퓨터
2. 분산 메모리 시스템 (Distributed Memory System)
- 병렬처리 시스템 내에서 각 연산장치(프로세서)가 독립적인 메모리 공간을 가지고, 교환이 필요한 경우 명시적인 통신을 해야하는 병렬 처리 시스템이다.
- 통신 부하가 매우 큰 편으로 통신 부하를 줄이기 위한 노력은 효율적인 병렬처리 알고리즘을 설계하는데 매우 중요한 요소이다.
그렇다면 GPU는?
GPU는 SIMD구조에 속하며 데이터 수준 병렬 처리에 적합한 하드웨어다.
하지만 GPU는 일반적으로 SIMD(Single Instruction - Multi Data)가 아닌 SIMT(Single Instruction - Multi Thread)로 구분된다.
SIMT
한 스레드 그룹 내 스레드들을 하나의 제어 장치로 제어한다.
- SIMD와 유사하게 하나의 제어장치가 여러개의 코어를 제어한다. 하지만 SIMT에서는 제어하는 그룹의 단위가 스레드이다.
각 스레드는 자신만의 제어 문맥을 갖니다.
- SIMT에서는 스레드가 자신만의 제어 문맥을 갖는다. SIMD의 경우 여러 데이터에 대해 동일한 명령을 적용한다. 하지만 SIMT의 경우 하나의 제어 장치가 여러 개의 스레드를 제어할 수 있기에 서로 독립된 제어 문맥을 가질 수 있다.
그룹 내 스레드들 사이의 분기가 허용된다.
- SIMT에서 각 스레드가 독립된 제어 문맥을 가지기 때문에, 분기문을 허용한다.
병렬 처리 성능 지표
속도향상 (Speedup) = 직렬처리에 걸린 시간 / 병렬 처리에 걸린 시간
만약 직렬 처리에 10초가 걸렸는데, 병렬 처리에서는 5초가 걸렸다고 한다.
그러면 10 /5 = 2, 즉 2배가 빨라졌다고 볼 수 있다.
그럼 이게 좋은 알고리즘일까? 연산 장치의 숫자를 보면 알 수 있다.
만약 10개의 연산 장치를 사용했다면, 10배 빨리지는 것이 이상적인 속도 향상일 것이다.
그때는 2배 빨라진 것이 좋은 알고리즘이라고 불리기 어려울 것이다.
이처럼 사용한 연산장치의 수 만큼 빨라지는 것을 Linear Speedup이라고 부른다.
병렬 처리의 실제 수행 시간은 다음 수식과 같다.
병렬T = 직렬T / P(연산 장치 수) + 병렬 처리로 발생한 부하
이 식만을 가지고 속도 향상 성을 판단하기는 어렵다. 아래식을 추가로 보자
효율E = S(speed up) / P(연산 장치 수) = (직렬T / 병렬T) / P(연산 장치 수)
= 직렬T / (P * 병렬T)
연산 장치 수가 증가함에 따라 병렬 처리를 얼마나 잘 유지하는지를 병렬 처리 알고리즘 확장성(Scalability)라고 한다.
'ComputerGraphics > 책' 카테고리의 다른 글
| [RealTimeRendering-4th] Transforms (3) (0) | 2024.10.18 |
|---|---|
| [RealTimeRendering-4th] Transforms (2) (0) | 2024.10.18 |
| [CUDA기반 GPU병렬 처리 프로그래밍] 벡터 합 연산 (0) | 2024.10.17 |
| [RealTimeRendering-4th] Transforms (1) (0) | 2024.09.20 |
| [RealTimeRendering-4th] The Graphics Rendering Pipeline (0) | 2024.09.09 |



