History... 딱히 넘어가도...
LeNet (1989)
MNIST 손글씨 인식, OCR의 시초
ImageNet(2009)
사물을 분류하는 데이터 셋
일반적인 이미지 인식 능력을 평가/학습할 수 있는 대규모 데이터 셋
대규모 데이터셋에 모델을 처음부터 학습시키는 것을 Pretraining 이라고 한다.
데이터를 넣는데 한계가 있었기 때문에 underfitting이 심했지만, deep learning을 통해 해결
Pretraining 이란
Fine Tuning(Transfer Learning): Pretraining 된 모델을 다시 다른 데이터셋에 학습시키는 것
Pretraining Data Size > Transfer Learing Data Size
Pretraining Data &Transfer Learing Data 비슷하면 좋다.
유사성이 없어도, 데이터 형태(tensor)만 같아도 random initialization보다 좋은 성능을 보일 때가 있다.
AlexNet(2012)
Neural Network 모델로 최초로 Imagenet에서 우승
2차 AI겨울 종료
CUDA kernel에서 Convolution 구현
GTX580 2대로 5-6일간 학습
Sigmod / tanh -> ReLU도입 (gradient vanishing 해결)
VGGNet(2014)
kernel size 3x3으로 고정시키고, 깊고(layer를 늘리고) 넓게(channel을 늘리고) 모델링하였다.
layer를 늘린다 + kernel size를 3x3 고정의 의미는
5x5 kernel의 layer하나와 3x3 kernel의 layer 2개가 같은 receptive field를 지니기 때문에
layer를 늘리는걸로 퉁~
receptive field : 시야
CNN의 학습법
1. Pattern Recognition
cnn은 패턴을 kernel에 저장하고, kernel과 비슷한 패턴에서 큰 값을 반환하는 형태로 동작한다.
만약 kernel이 눈 모양일 때, 눈 외에서는 0과 비슷하게 반환하다가, 눈에서 큰 값을 반환한다.
입력층에 가까울수록 low-level feature(윤곽선과 같은..),
출력층에 가까울수록 high-level feature(도드라지는? 특징 같은...)

중요한건 우리가 kernel마다의 역할을 정해주는 것이 아니다
backpropagation을 통해 End-to-End로 모델이 학습하는 것이다.
2. Feature Extraction
Spatial feature(픽셀의 정보)의 정보를 Semantic feature(의미있는 특징점)정보로 바꿔나가는 것이다.
Pooling layer를 통해서 low-level feature를 high-level-feature로 변환해준다.
(처음에는 단순한 feature만 필요해서 적은 채널을 사용하지만, 점점 복잡하고 다양한 feature를 담기 위해 채널 수를 늘려간다.)

결론
대규모 데이터 셋에서는 Model의 Capacity가 증가해야 성능이 좋아진다.
Capacity 증가 => Channel size 확대 or layer 추가
그렇다면 Capacity를 증가시키기 위해서 layer를 쌓았을 때 반작용은 없는가..!
Deep Network 학습 시 발생하는 문제점
Deep Neural Network를 학습할 때 여러 문제가 발생할 수 있는데, 그중 중요한 문제 중 하나는 Internal Covariate Shift이다.
Internal Covariate Shift란?
Neural Network를 학습할 때 각 Layer 을 통과하면서 데이터의 분포 (평균, 분산) 가 계속 바뀌는 현상을 말한다.
즉, 앞쪽 Layer에서 나온 값(activation) 들이 뒤 Layer로 갈 때마다 평균, 분산이 바뀌는 것이다.
=> Gradient 계산에 영향을 줘서 Vanishing Gradient or Exploding Gradient문제를 일으킬 수 있다.
=> 학습이 어려움, 성능 악
Internal Covariate Shift 해결을 위한 Rule of Thumb
1. 각 hidden layer의 출력값(activation)의 평균은 0으로 유지해야된다.
2. 각 hidden layer의 출력값(activation)의 분산은 모두 동일해야된다.
Internal Covariate Shift를 방지하기 위한 Initializer
초가값을 너무 작게하면 -> Vanishing Gradient
초기값을 너무 크게하면 -> Exploding Gradient
그래서 위해서 말한 Rule of Thumb를 지켜줘야된다.
1. 각 hidden layer의 출력값(activation)의 평균은 0으로 유지해야된다. (=> E(z) == 0)
z = w1x1 + w2x2 + ... + wnxn 으로 나오는데 E(z)가 0이 되기 위해서는 E(w1), E(w2) ....가 0이 되면 된다.
=> E(w) = 0으로 결론이난다.
2. 각 hidden layer의 출력값(activation)의 분산은 모두 동일해야된다. (=> Var(x) == Var(z))
Var(z) = Var( w1x1 + w2x2 + ... + wnxn ) = n * Var(w) * Var(x)
Var(x) = Var(z) 이여야 하니까 Var(z)에 얻은 식을 대입해주면
Var(w) = 1 / n을 얻을 수 있다.
결론:
평균 조건: E(w) = 0
분산 조건: Var(w) = 1 / n
Internal Covariate Shift를 방지하기 위한 Normalizer
입력 X값이 너무 크거나 / 작거나 / 일정하다면
입력과 출력을 normalization을 해주면, internal covariate shift를 직접적으로 해결할 수 있다.
normalization을 적용하는 축에 따라 Batch Normalization, Layer Normalization등이 존재한다.
batch : channel에 대해서 normalization
layer: sample에 대해서 normalization


Batch Normalization (BN)
input batch의 각 feature(unit, channel) 를 Normalize해준다. (CNN, Continuous Data에서 주로 사용된다.)

순서는 주로 Conv -> Batch Normalization(BN) -> Activation 순으로 해준다.
(BN에 bias가 존재해서 Conv에서는 bias를 따로 사용하지 않는다.)

추론/평가에서는 학습과 다르게 작동한다.
그 이유는 batch의 통계(평균, 분산)에 의존적이기 때문이다.
=>batch에 존재하는 값에 따라 평균(mean)값이 달라짐, batch size에 따른 값이 달라짐
그래서 추론할 때 사용할 고정값 statistics μ, σ^2 를 선택해서 고정해야된다.
학습할 때 μ, σ^2의 moving average를 미리 저장해두고, 추론/평가시에 사용한다.
(training data 와 test data의 괴리가 크거나, Pretraining 모델을 가져와 Fine-tuning 시 초기 μ, σ²가 맞지 않는 문제 등 작동이 잘 안되는 경우도 있다.)
Layer Normalization
input batch의 각 sample을 Normalize해준다. (RNN, Sequential Data에서 주로 사용된다.)
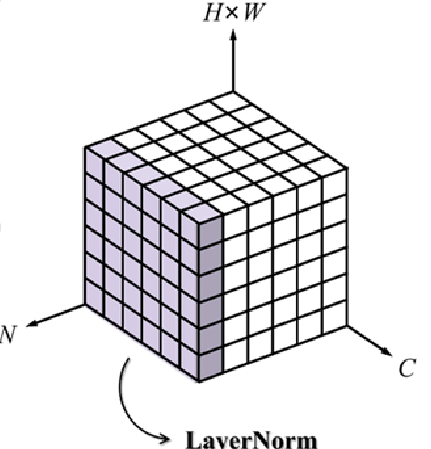

추론할 때 그냥 사용해도 괜찮다.
sample 별로 normalization해서 평균, 분산을 구하기 때문에 batch별로 달라지지 않는다.
ResNet
이렇게 Internal Covariate Shift를 initializer와 normalization을 통해 해결해서
ResNet(2015)과 같은 모델이 Deeper Networks가 가능해졌다...!
ResNet: Residual Connection
방법은 간단하다.
이전 layer의 출력값을 현재 layer의 출력 값에 더해주는 것이다.


layer 수가 많아지면 loss landscape의 굴곡이 심해져 학습하기 어려웠는데, residual connection은 이를 평탄화 해준다.
논리적으로도... layer마다 새로운 정보를 학습하는 것보다 이전 layer에서 학습하지 못한 것을 추가학습하는 것이 더 쉬울 것이다.
우측 그림을 보면, backpropagation을 할 때 지름길도 생긴다.. ㅎㅎ
이를 통해 gradient vanishing 문제가 완화된다.
대부분의 모델들은 residual connection을 사용한다.
ResNet: Pointwise Convolution
Pointwise Convolution은 1x1 커널을 사용하는 단순한 형태의 합성곱이다.
최종적으로 계산 과정을 보면 Fully Connected Layer (Dense Layer) 와 동일한 방식으로 채널 축에 대한 연산을 수행한다.
이는 각 위치 (spatial position) 에서 채널들 사이의 관계를 학습하는 것으로,
기존의 high-level feature들을 조합하여 새로운 feature 표현을 생성하는 역할을 한다.
따라서, 채널 간의 정보를 섞어서 재구성하는 효과가 있다.

ResNet: Bottleneck Architecture
50개 이상의 레이어를 가진 ResNet (ex. ResNet-50, ResNet-101, ResNet-152) 에서 사용되는 효율적인 블록 구조이다.
깊은 네트워크에서도 계산량을 줄이고 성능을 유지하기 위해 고안된 방식이다.
1x1 Conv( Pointwise Conv )로 demension을 줄이고(중요한 feature를 선택하도록 유도한다.)
3x3 Conv 로 학습하고
1x1 Conv( Pointwise Conv )로 demension을 복구 시킨다.

ResNet: Global Average Pooling
channel 별 평균을 구해서 사용하는 방법이다.
이게 가능한 이유는
많은 layer를 통해서 spatial information 에서 semantic informaion으로 충분히 변환이 되었기 때문에 flatten을 대체할 수 있는 것이다.

또한 shift invaiance 확보까지 가능하다
=>파란 원에 obect가 있나, 빨간 원에 object가 있나 값은 동일하다.

기존 VGG-Net에서는 input-output간의 parameter가 의존적이었는데,
ResNet은 이를 벗어났다. (transfer learning에 유리해졌다. input을 원하는 데이터로 줄 수 있다. 자유성이 높아진거지요)
'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝] RNN_decoding_padding_한계(2) (0) | 2025.03.19 |
|---|---|
| [딥러닝]CNN_Regularization(3) (0) | 2025.03.17 |
| [딥러닝] CNN_기본(1) (0) | 2025.03.16 |
| [딥러닝] MLP - 2 (0) | 2025.03.14 |
| [딥러닝] MLP(Binary, Multiclass, Multilabel Classification) - 1 (0) | 2025.03.14 |



